ANTLR
Ashley J.S Mills
<ug55axm@cs.bham.ac.uk>
Copyright © 2002 The University Of Birmingham
Traduzione: N. Fanizzi
2005 Università degli Studi di
Bari
Indice
- Introduzione
- Informazioni di Base
- Il Lexer
- Il Parser
- Qual è
il ruolo di ANTLR in tutto ciò?
- Installazione
- Modello di Grammatica ANTLR
- Notazione ANTLR
- Zero o Più
- Uno o Più
- Opzionalità
- Esempio di Lexer
- Un Semplice Esempio di
Lexer/Parser
- Esempio di Valutazione di
Espressioni
- Estensione della
Valutazione delle Espressioni
- Espressioni
Nidificate
- Aggiunta
dell'Operatore Segno
- Un Esempio di Traduzione:
da CSV ad una Tabella XHTML
- Estratti
da dietro le Quinte
- Ringraziamenti
- Bibliografia (e link utili)
1. Introduzione
ANTLR (ANother Tool for Language Recognition) è uno
strumento generatore di parser e traduttori che permette di definire
grammatiche sia nella sintassi ANTLR (simile alla EBNF e a quella di
YACC) sia in una speciale sintassi astratta per AST (Abstract Syntax
Tree). ANTLR può creare scanner, parser e AST. ANTLR è
tuttavia qualcosa di più di un linguaggio di definizione di
grammatiche, gli strumenti forniti permettono di implementare la
grammatica definita in ANTLR generando automaticamente scanner, e
parser (o tree parser) sia in Java (http://java.sun.com/),
C++ (http://anubis.dkuug.dk/jtc1/sc22/wg21/)
oppure Sather (http://www.icsi.berkeley.edu/~sather/).
ANTLR implementa una strategia di analisi sintattica PRED-LL(k) e
consente un lookahead di lunghezza arbitraria per disambiguare nei
casi di ambiguità. Una risposta alla domanda "Cos'è
ANTLR?" da parte di Terrance Parr creatore di ANTLR si può
trovare presso: http://www.jguru.com/faq/view.jsp?EID=77
2. Informazioni di
Base
ANTLR è uno strumento per compilatori per cui l'ambito di
sviluppo è generalmente ristretto a coloro che desiderano
creare traduttori di qualche tipo. Per comprendere a pieno quanto
sarà esposto in questo tutorial è necessario per
iniziare a familiarizzare con la terminologia usata in questa area
dell'informatica e i concetti basilari sottesi dal funzionamento di
ANTLR. Questa sezione parte da una breve esposizione su come funziona
un compilatore.
2.1. Il Lexer
Altri nomi: Scanner, analizzatore lessicale, tokenizzatore.
I linguaggi di programmazione sono fatti di parole-chiave, e
costrutti definiti in modo preciso, scopo principale del processo di
compilazione è quello di tradurre le istruzioni ad alto
livello del linguaggio di programmazione nelle istruzioni di basso
livello del linguaggio macchina o di una macchina virtuale che
rappresenta l'architettura per l'esecuzione. Per esempio, un
compilatore C++ nativo compila codice C++ in istruzioni di codice
macchina da eseguirsi sull'hardware di riferimento (o su emulatori di
tale hardware), il compilatore Java standard distribuito dalla Sun
Microsystems compila codice sorgente Java in bytecode Java che è
il set di istruzioni di macchina usato dalla Java virtual machine,
questo bytecode può quindi essere eseguito su qualsiasi
piattaforma che implementi la Java virtual machine.
Un programma sorgente viene scritto mediante un editor che può
produrre un file fatto di istruzioni e costrutti consentiti dal
linguaggio di programmazione in uso. Il testo reale effettivo del
file viene scritto usando caratteri di un particolare insieme o
sottoinsieme di un set, pertanto un sorgente può essere
considerato come un flusso di caratteri terminanti con un marcatore
di fine file EOF (End Of File)
Un file sorgente viene inviato come flusso ad un lexer carattere
per carattere da una qualche interfaccia di input. Il lavoro del
lexer è impacchettare il flusso di caratteri (altrimenti)
insignificante in gruppi che, elaborati dal parser, acquistano
significato. Ogni carattere o gruppo di caratteri raccolto in questo
modo viene detto token. I token sono componenti del linguaggio di
programmazione in questione come parole chiave, identificatori,
simboli ed operatori. (Di solito) il lexer rimuove commenti e
spaziatura dal programma, ed ogni altro contenuto che non ha un
valore semantico per l'interpretazione del programma. Il lexer
converte il flusso di caratteri in un flusso di token che hanno un
significato individuale stabilito dalle regole del lexer.
Analogamente, il vostro cervello sta probabilmente raggruppando in
token (parole, in tal caso, con un valore semantico per voi) i
singoli caratteri che compongono questa frase, il vostro lavoro di
determinare dove finisce un token e ne inizia un altro è
facilitato, tuttavia, dal fatto che le parole nella frase sono già
separate dagli spazi, in tal senso si potrebbe affermare che una
frase in italiano è già tokenizzata, tuttavia si può
assumere che una forma di raggruppamento e di riconoscimento avvenga
anche a livello di parole. Il flusso di token generato dal lexer
viene ricevuto in ingresso dal parser.
Un lexer di solito genera errori riguardanti le sequenze dei
caratteri che non riesce a mettere in corrispondenza con gli
specifici tipi di token definiti dalle sue regole.
2.2. Il Parser
Altri Nomi: analizzatore sintattico.
Un lexer raggruppa sequenze di caratteri che riconosce nel flusso
dotate di un valore semantico individuale. Esso non considera il loro
valore semantico nel contesto dell'intero programma poiché
questo è dovere del parser. I linguaggi sono descritti
attraverso grammatiche. Una grammatica determina esattamente quello
che definisce un dato token e quali sequenze di token sono
considerate valide. Il parser organizza i token che riceve in
sequenze ammesse definite della grammatica del linguaggio. Se il
linguaggio viene usato esattamente come definito nella grammatica, il
parser sarà in grado di riconoscere i pattern che
costituiscono specifiche strutture del discorso e raggrupparle
insieme opportunamente. Se il parser incontra una sequenza di token
che corrisponde a nessuna delle sequenze consentite, solleverà
un errore e forse proverà a recuperarlo facendo alcune
assunzioni sulla natura di tale errore.
Il parser controlla che il token si conformi alla sintassi del
linguaggio definita dalla grammatica. Analogamente il vostro cervello
conosce quali tipi di frase sono validi in un dato linguaggio
naturale come l'italiano e si potrebbe dire che in questo preciso
momento il vostro cervello sta parserizzando le parole di questa
frase e le sta raggruppando in quello che si intende come frasi
valide. Per esempio, il cervello sa che una sentenza termina quando
si incontra un punto, allora non si dovrebbe considerare il testo che
segue il punto come parte della stessa frase. Oltre a questo, il
cervello estrae dalla frase dell'informazione significativa. Di
solito il parser converte le sequenze di token per le quali è
stato costruito facendole corrispondere ad un altra forma come un
albero sintattico astratto (AST). Un AST è
più facile da tradurre in un linguaggio obiettivo poiché
contiene implicitamente informazione aggiuntiva per la natura della
sua struttura. Indubbiamente, creare un AST è la parte più
importante nel processo di traduzione del linguaggio.
Il parser genere una o più tavole dei simboli che
contengono informazione riguardante i token incontrati, ad esempio se
il token è il nome di una procedura o meno oppure se aveva
qualche valore specifico. Le tavole dei simboli sono impiegate nella
generazione del codice oggetto e nel controllo sui tipi, ad esempio,
in modo che un intero non venga assegnato ad una stringa ecc. ANTLR
usa le tavole dei simboli per velocizzare il processo di trovare la
corrispondenza (match) dei token per il fatto che un intero viene
mappato con un particolare token, invece di cercare la corrispondenza
con la stringa della sua rappresentazione testuale, il che è
molto più veloce. Alla fine l'AST viene tradotto in un formato
eseguibile, potrebbe essere anche realizzato il linking di qualche
libreria che, non essendo considerato compito da compilatore, non
verrà ulteriormente trattato nel seguito.
Un parser di solito genera errori che attengono alle sequenze di
token che non riesce a far corrispondere alle specifiche strutture
sintattiche consentite, come stabilito dalla grammatica.
I lexer e i parser sono entrambi riconoscitori: i lexer
riconoscono sequenze di caratteri, i parser riconoscono sequenze di
token. Un lexer o n parser converte un flusso di elementi (siano essi
caratteri o token) traducendoli in altri flussi di elementi, come i
token, che rappresentano strutture più ampie o gruppi di
elementi o nodi in un AST. Essi sono essenzialmente la stessa cosa,
però tradizionalmente gli analizzatori sintattici sono
associati ai flussi di elaborazione dei caratteri mentre i parser
sono legati ai flussi di token.
Si raccomanda la lettura di Building Recognizers By Hand
di Terence Parr creatore di ANTLR, che si può trovare qui
http://www.antlr.org/book/byhand.pdf,
per approfondire cosa fare accingendosi a creare un riconoscitore in
Java, e da questo si può astrarre come questo possa essere
fatto in qualunque altro linguaggio di programmazione. Avendone il
tempo occorrerebbe leggere tutta la documentazione a corredo
dell'installazione di ANTLR.
2.3. Qual è
il ruolo di ANTLR in tutto questo ?
ANTLR permette la definizione di regole che il lexer dovrebbe
seguire per tokenizzare un flusso di caratteri e regole che il parser
deve usare per interpretare il flusso di token. ANTLR è in
grado di generare un lexer ed un parser che si può usare per
interpretare programmi scritti in un linguaggio e tradurli in altri
linguaggi e AST. Il progetto di ANTLR consente molta estensioni ed ha
molte applicazioni.
3. Installazione
La documentazione per l'installazione viene riportata sotto
l'assunzione che il lettore abbia qualche esperienza
sull'installazione di software sui computer e sappia come cambiare
l'ambiente d'elaborazione del particolare sistema operativo in uso. I
documenti intitolati Configurare un
ambiente di lavoro Windows e Configurare
un ambiente di lavoro Unix sono utili a chi ha bisogno di
saperne di più.
Scaricare ANTLR dai seguenti link della sezione di download
presso http://www.antlr.org/
Decomprimere in una data locazione.
Aggiungere
/percorso/per/dove/si/trova/ANTLR/antlr.jar
e
/percorso/per/dove/si/trova/ANTLR
alla
propria variabile classpath; non includere lo slash finale
dopo il nome della directory per non avere problemi.
4. Modello di Grammatica di
ANTLR
Un file di grammatica di ANTLR ha un certo numero di componenti,
alcune delle quali sono opzionali mentre altre sono obbligatorie. Il
'modello' sottostante mostra tutte le componenti che costituiscono un
file di grammatica ANTLR e quindi le descrive. Non ci si aspetti di
comprendere tutti immediatamente. Le cose diventeranno più
chiare man mano che ci si addentra in questo documento. Si può
usare questo modello per ricordare a se stessi quello che è
ammissibile in una grammatica ANTLR.
header {
// tutto quanto va replicato in ogni file generato
}  options { opzioni per l'intero file di grammatica }
{ preambolo di classe opzionale - output per il file di classe generato
immediatamente prima della definizione della classe }
class YourLexerClass extends Lexer;
// la definizione si estende da qua alla prossima definizione di classe
// (oppure EOF se non ci solo altre definizioni di classe)
options { VostreOpzioni }
tokens...
options { opzioni per l'intero file di grammatica }
{ preambolo di classe opzionale - output per il file di classe generato
immediatamente prima della definizione della classe }
class YourLexerClass extends Lexer;
// la definizione si estende da qua alla prossima definizione di classe
// (oppure EOF se non ci solo altre definizioni di classe)
options { VostreOpzioni }
tokens...
 regole del lexer...
myrule[args] returns [retval]
options { defaultErrorHandler=false; }
: // corpo della regola...
;
{ preambolo di classe opzionale - output per il file di classe generato
immediatamente prima della definizione della classe }
class YourParserClass extends Parser;
options { VostreOpzioni }
tokens...
regole del parser ...
{ preambolo di classe opzionale - output per il file di classe generato
immediatamente prima della definizione della classe }
class YourTreeParserClass extends TreeParser;
options { VostreOpzioni }
tokens...
regole del parser ad albero...
// altri lexer, parser e treeparser posono essere inclusi
regole del lexer...
myrule[args] returns [retval]
options { defaultErrorHandler=false; }
: // corpo della regola...
;
{ preambolo di classe opzionale - output per il file di classe generato
immediatamente prima della definizione della classe }
class YourParserClass extends Parser;
options { VostreOpzioni }
tokens...
regole del parser ...
{ preambolo di classe opzionale - output per il file di classe generato
immediatamente prima della definizione della classe }
class YourTreeParserClass extends TreeParser;
options { VostreOpzioni }
tokens...
regole del parser ad albero...
// altri lexer, parser e treeparser posono essere inclusi
|
|
|
header {
// tutto quanto va replicato in ogni file generato
}
|
|
Il contenuto testuale dell'header sarà
copiato letteralmente in cima a tutti i file generati facendo
girare ANTLR sulla grammatica.
|
|
|
{ preambolo di classe opzionale - output per il file di classe generato
immediatamente prima della definizione della classe }
class YourLexerClass extends Lexer;
// la definizione si estende da qua alla prossima definizione di classe
// (oppure EOF se non ci solo altre definizioni di classe)
options { VostreOpzioni }
tokens...
regole del lexer...
|
|
Questa parte inizia con un preambolo opzionale di classe,
qualunque testo messo qui sarà copiato letteralmente in
cima alla classe che questa istruzione precede. La sezione opzioni
contiene specifiche opzioni per questa classe, ad esempio:
|
|
options {
k = 2; // pone a due il lookahead di token
tokenVocabulary = Befunge; // chiama il suo vocabolario "Befunge"
defaultErrorHandler = false; // non genera gestori di errori di parser
}
|
|
Maggiori dettagli riguardanti le varie opzioni
disponibili possono essere trovate nella documentazione di ANTLR
che viene installata con tutto il resto, cioè
/percorso/per/dove/si/trova/ANTLR/doc/options. La sezione
token permette di definire esplicitamente letterali e token
immaginari, per es.:
|
|
tokens {
EXPR; // token immaginario
THIS="that"; // definizione di letterale
INT="int"; // definizione di letterale
}
|
|
Quindi vengono le regole del lexer della forma
generale:
|
|
rulename [args] returns [retval]
options { defaultErrorHandler=false; }
{ codice opzionale di inizializzazione }
: alternativa_1
| alternativa_2
| alternativa_n
;
|
|
Ad esempio:
|
|
INT : ('0'..'9')+; // Corrisponde ad un intero
|
|
Ci può essere un numero arbitrario di regole.
|
Le altre due sezioni hanno la stessa struttura di quella
descritta. Ci possono essere zero o più lexer, parser e parser
ad albero ed essi possono apparire in qualsiasi ordine. La visibilità
di una classe si estende per definizione dalla dichiarazione della
classe fino alla successiva dichiarazione di classe, o a fine file se
si tratta dell'ultima dichiarazione di classe.
5. Notazione ANTLR
ANTLR specifica le sue regole lessicali e sintattiche usando quasi
esattamente la stessa notazione. La notazione di ANTLR è
basata su quella di YACC e vi è anche un buon numero di
costrutti EBNF. Una regola è semplicemente una sequenza di
istruzioni che descrivono un particolare pattern con cui ANTLR
dovrebbe trovare una corrispondenza.
5.1. Zero o Più
ANTLR usa la notazione (espressione)* per indicare che
l'espressione con cui trovare la corrispondenza specificata tra le
parentesi deve essere trovata zero o più volte.
5.2. Uno o Più
ANTLR usa la notazione (espressione)+ per indicare che
l'espressione con cui trovare la corrispondenza specificata tra le
parentesi deve essere trovata una o più volte.
5.3. Opzionalità
ANTLR usa la notazione (espressione)? per indicare che
l'espressione con cui trovare la corrispondenza specificata tra le
parentesi deve essere trovata zero o una volta, in altre parole, è
opzionale.
6. Esempio di Lexer
Questo esempio illustra un vero lexer semplificato che cerca la
corrispondenza con stringhe alfabetiche o numeriche. Si trova da
scaricare scaricabile qui: simple.g.
class SimpleLexer extends Lexer;
options { k=1; filter=true; }
ALPHA : ('a'..'z'|'A'..'Z')+
{ System.out.println("Found alpha: "+getText()); }
;
NUMERIC : ('0'..'9')+
{ System.out.println("Found numeric: "+getText()); }
;
EXIT : '.' { System.exit(0); } ;
|
Questo verrà spiegato per passi. Iniziamo dalla prima
linea:
class SimpleLexer extends Lexer;
|
Questa è la dichiarazione del lexer in buona sostanza. Il
suo ambito va dalla linea mostrata fino alla prossima dichiarazione
di classe o, se non ci sono più classi, fino a fine file.
options { k=1; filter=true; }
|
Ecco come settare alcune opzioni di base. k è
settata ad uno. k è il quantitativo di lookahead. Per
esempio, con un lookahead di uno, ANTLR non sarebbe in grado di
stabilire la differenza tra:
SILLY1 : "ab" ;
SILLY2 : "ac" ;
|
E quando si cerca di analizzare un file contenente queste regole
di lexer, ANTLR solleverebbe un errore:
warning: lexical nondeterminism between rules SILLY1 and SILLY2 upon
silly.g:0: k==1:'a'
|
Qualora il lexer incontrasse ab, con un lookahead
di uno, si avrebbe una confusione sulla corrispondenza con la regola
SILLY1 e SILLY2 dato che entrambe
iniziano per 'a'. Con k=2, cioè un lookahead
di due, il lexer non comparerebbe solo il primo carattere ma anche il
secondo e perciò sarebbe capace di disambiguare tra i due
casi. Ci sono casi in cui incrementando il lookahead non funziona o
non è la soluzione più; efficiente. Questi casi saranno
esaminati in un'altra sezione. E' interessante il fatto che, se si
implementa davvero questo esempio con k=1, la regola
troverebbe la corrispondenza con ab ma non con ac
perché ANTLR si ferma sempre alla prima regola definita tra
quelle ambigue
L'opzione filter=true abilita il filtraggio, che
significa che il lexer ignorerà qualunque input che non
corrisponde esattamente ad una delle regole non protette (le regole
protette possono solo essere richiamate da altre regole). L'opzione
può essere anche settata al nome di una regola protetta per
affidare ad una particolare regola la gestione dei casi di non
corrispondenza. Per esempio:
options { filter=BLAH; }
protected BLAH : { _ttype = Token.SKIP; } ;
|
ha lo stesso effetto del settare il filtraggio a true.
Tuttavia, usare il filtraggio come è stato appena mostrato non
è raccomandabile dato che questo tipo di utilizzazione sarebbe
completamente ridondante.
ALPHA : ('a'..'z'|'A'..'Z')+
{ System.out.println("Found alpha: "+getText()); }
;
|
Questo è un esempio di regola di lexer. Corrisponde ad ogni
sequenza di uno o più caratteri indicata dagli intervalli
specificati. Il '+' significa che vale ogni sequenza di
quanto viene specificato nel gruppo precedente. In questo caso o
qualunque cosa nell'intervallo di caratteri 'a'..'z' oppure
'A'..'Z'. Gli intervalli sono separati da un carattere '|'
che corrisponde ad un OR logico. Viene specificata anche un'azione
per questa regola che sarà eseguita in caso di corrispondenza.
L'azione riguarda semplicemente un'istruzione di stampa che indica il
fatto che un token alfabetico è stato trovato e la stringa
relativa viene stampata con una chiamata a getText() che
restituisce la versione testuale del token relativo.
NUMERIC : ('0'..'9')+
{ System.out.println("Found numeric: "+getText()); }
;
|
Questa è molto simile alla regola ALPHA ma
invece corrisponde a sequenze di uno o più caratteri
nell'intervallo '0'..'9'. Se c'è corrispondenza si
stampa un messaggio che indica il ritrovamento di un token di tipo
numerico e quindi si stampa il relativo testo.
EXIT : '.' { System.exit(0); } ;
|
Questa regola corrisponde letteralmente al carattere '.'
(un '.' non racchiuso tra apici può andare anche
all'interno delle regole come carattere jolly che corrisponde
all'occorrenza di "un qualunque carattere". L'azione
intrapresa quando vale questa regola è di uscire dal programma
con uno stato di uscita di zero che vuol dire che il programma è
terminato normalmente.
-
|
![[Note]](images/note.png)
|
Note
|
|
Usando l'opzione filter=true, se si
elaborano file normali, allora occorre anche includere sempre una
regola per il ritorno a capo, perché il lexer ha bisogno
che gli si dica quando c'è un ritorno a capo in modo da
incrementare il contatore di riga, altrimenti rimarrebbe bloccato
su una stessa riga! Una tipica regola per il ritorno a capo, che
mostra la chiamata al metodo newline() per gestire i
ritorni a capo correttamente viene mostrata qui sotto:
|
|
NEWLINE : ( "\r\n" // DOS
| '\r' // MAC
| '\n' // Unix
)
{ newline();
$setType(Token.SKIP);
}
;
|
|
La direttiva ANTLR $setType(tokenType)
si usa per indicare che queste sequenze di caratteri dovrebbero
essere ignorate.
|
Dopo aver definito il nostro lexer, ANTLR gira sul file sorgente
per generare i vari file Java (o C++ o Sather):
Il comando mostra le informazioni sulla versione e quindi, se non
sono presenti errori nel file sorgente, genera i file di output. Se
ci sono errori nel sorgente e vengono rilevati allora vengono
mostrati dei bei messaggi che li descrivono. Se gli errori non sono
gravi, i file saranno comunque creati e in genere una qualche forma
di output viene prodotta. tuttavia potrebbero non risultare
compilabili per via di tali errori. Il testo prodotto allorché
vengono incontrati errori può risultare molto informativi come
la seguente, generato per aver deliberatamente omesso il carattere di
terminazione ';' della regola nella fine di una regola:
ANTLR Parser Generator Version 2.7.1 1989-2000 jGuru.com
simple.g:13: warning:did you forget to terminate previous rule?
|
Il numero di linea indicato è l'inizio della regola che
segue quella in cui ci si è dimenticati di terminare. In tal
caso, ANTLR recupera in qualche modo l'errore e i file di output
vengono comunque prodotti come desiderato. I file di output generati
sono SimpleLexer.java e SimpleLexerTokenTypes.java.
SimpleLexer.java, il lexer prodotto, implementa
TokenStream il che significa che restituirà il
prossimo token nel flusso di token quando qualcuno chiama nextToken()
da una istanziazione di SimpleLexer (o quale che sia il nome
del lexer). Essa contiene metodi che sono discussi in maggior
dettaglio nella documentazione di ANTLR.
SimpleLexerTokenTypes.java contiene le definizioni dei
tipi di token definite come costanti intere, per rendere il
efficiente confronto in fase di esecuzione. Le tavole dei token sono
anche impiegate per il controllo sui tipi prima della traduzione. Per
usare il lexer un qualche tipo di programma deve invocarlo. Ecco un
programma Java che fa proprio questo:
import java.io.*;
public class Main {
public static void main(String[] args) {
SimpleLexer simpleLexer = new SimpleLexer(System.in);
while(true) {
try {
simpleLexer.nextToken();
} catch(Exception e) {}
}
}
}
|
Viene creata una nuova istanza di SimpleLexer con
il costruttore SimpleLexer(InputStream in) che viene
generato automaticamente. Si entra in un ciclo infinito che continua
a richiedere il prossimo token dal flusso di input. Questo flusso è
System.in il che significa che viene accettato input
attraverso la linea di comando e l'input verrà passato allo
scanner ogni volta che viene premuto il tasto di invio (per questo
non serve la gestione del ritorno a capo).
Tutti i file Java sono compilati richiedendo:
Il file Main.class prodotto viene eseguito chiedendo:
Una sessione d'esempio che fa uso di questo lexer viene mostrata
di seguito:
This Lexer recognises strings and numbers: hello 22 goodbye 33
Found alpha: This
Found alpha: Lexer
Found alpha: recognises
Found alpha: strings
Found alpha: and
Found alpha: numbers
Found alpha: hello
Found numeric: 22
Found alpha: goodbye
Found numeric: 33
It ignores everything else: -=+/#
Found alpha: It
Found alpha: ignores
Found alpha: everything
Found alpha: else
.
|
Questo lexer riconosce esclusivamente contenuto alfabetico e
numerico. Se gli si passa la stringa "11aa33hi"
non la tratterà come una stringa singola ma la decomporrà
in parti alfabetiche e numeriche, come è stato detto di fare:
11aa33hi
Found numeric: 11
Found alpha: aa
Found numeric: 33
Found alpha: hi
.
|
Questo conclude questa breve introduzione ai lexer ma si deve
notare che di solito un lexer viene usato in combinazione con un
parser. Questo esempio è pensato interamente per illustrare
alcuni dei concetti. Si dovrebbe consultare la documentazione di
ANTLR e verificare gli altri esempi in questo testo per avere una
comprensione più completa del ruolo dei lexer nel processo di
traduzione
7. Un Semplice Esempio di
Lexer/Parser
Verrà esaminato un semplice parser e lexer. Il lavoro del
lexer sarà di tokenizzare il flusso di input in token; NAME,
AGE, DOB (Date Of Birth, ossia data
di nascita) e SEMI (semicolon, ossia punto e
virgola). Il lavoro del parser sarà di riconoscere la
sequenza DOB NAME AGE(SEMI) e restituirla come Name:
name, Age: nn, DOB: nn/nn/nn. Il lexer e il parser saranno
definiti nello stesso file simple2.g:
class SimpleParser extends Parser;
entry : (d:DOB n:NAME a:AGE(SEMI)
{
System.out.println(
"Name: " +
n.getText() +
", Age: " +
a.getText() +
", DOB: " +
d.getText()
);
})*
;
class SimpleLexer extends Lexer;
NAME : ('a'..'z'|'A'..'Z')+;
DOB : ('0'..'9' '0'..'9' '/')=>
(('0'..'9')('0'..'9')'/')(('0'..'9')('0'..'9')'/')('0'..'9')('0'..'9')
| ('0'..'9')+ { $setType(AGE); } ;
WS :
(' '
| '\t'
| '\r' '\n' { newline(); }
| '\n' { newline(); }
)
{ $setType(Token.SKIP); }
;
SEMI : ';' ;
|
Il parser è la prima classe da specificare, tuttavia
l'ordine non conta. Viene considerata una pratica migliore da alcuni
quella di cominciare dal livello più astratto possibile e
quindi lavorare verso il basso, cioè top-down.
entry : (d:DOB n:NAME a:AGE(SEMI)
{
System.out.println(
"Name: " +
n.getText() +
", Age: " +
a.getText() +
", DOB: " +
d.getText()
);
})*
;
|
Si vede come la prima regola sia entry, questa è
la regola che sarà chiamata dal metodo main
per innescare l'analisi dell'input. essa dice che il parser dovrebbe
cercare un token DOB seguito da uno spazio seguito
da un token NAME, seguito da uno spazio seguito da
un token AGE e terminato con una token SEMI
che rappresenta il punto e virgola che si cerca (la ragione per
l'avere la classe SEMI tra parentesi è di
poter essere posta immediatamente dopo AGE senza che
ANTLR pensi che si stia provando a far riferimento a qualche token
chiamato AGESEMI):
Se si ha successo nel trovare questa sequenza di token, le
variabili indicate immediatamente prima dei nomi dei token (a
in a:AGE, ecc), assumerà i valori dei token di cui
sono prefisso allora un'azione verrà eseguita, questo viene
indicato dalla apertura della graffa, l'azione intesa è quella
di stampare "Name: nome, Age: nn, DOB: nn/nn/nn"
dove "n" sta per una cifra. Si noti l'ambito della
tonda aperta, la corrispondente parentesi occorre immediatamente dopo
la chiusura della graffa della sezione delle azioni. Fa da suffisso
un '*' che sta a significare che si potrebbe dover cercare la
corrispondenza con la sequenza da zero a più volte. Guardiamo
le definizioni di questi token nel lexer:
NAME : ('a'..'z'|'A'..'Z')+;
|
Una semplice sequenza di una o più lettere minuscole OPPURE
maiuscole.
DOB : ('0'..'9' '0'..'9' '/')=>
(('0'..'9')('0'..'9')'/')(('0'..'9')('0'..'9')'/')('0'..'9')('0'..'9')
| ('0'..'9')+ { $setType(AGE); } ;
|
Se DOB e AGE fossero stati
specificati come segue:
DOB : ('0'..'9')('0'..'9')'/' ('0'..'9')('0'..'9')'/' ('0'..'9')('0'..'9') ;
AGE : ('0'..'9')+ ;
|
ANTLR avrebbe sollevato l'avvertimento:
warning: lexical nondeterminism between rules DOB and AGE upon
simple2.g:0: k==1:'0'..'9'
|
Questo accade perché entrambe le regole menzionate iniziano
con '0'..'9'. Ciò significa (con un lookahead pari ad
uno) che se il lexer incontrasse una cifra, non saprebbe quale delle
istruzioni provare, quindi dovrebbe provare con la prima ma così
AGE non sarebbe mai controllata e il parser non
potrebbe mai trovare la sequenza che stava cercando.
Una contromisura sarebbe quella di specificare un valore di
lookahead di 3 per il parser, cioè includere un istruzione tra
le opzioni come la seguente:
Questo abiliterebbe il parser a considerare un massimo di tre
simboli futuri laddove si renda necessario disambiguare e vedrebbe
che incontrando due cifre seguite da uno slash allora dovrebbe
predire la strada per il token DOB e se invece non
trovasse la corrispondenza con questo terzo simbolo con uno slash
dovrebbe scegliere la strada per AGE.
Se ci fossero molte alternative, che sarebbero disambiguate
modificando il valore di lookahead allora è preferibile usare
il metodo di incrementare tale valore ma se c'è solo una o
pochissime alternative allora è preferibile usare invece un
predicato sintattico come quello usato nell'esempio. Il predicato
sintattico dell'esempio è:
DOB : ('0'..'9' '0'..'9' '/')=>
|
Questo dice che il lexer dovrebbe vedere se riesce a trovare due
cifre seguite da uno slash. Se sì allora il lexer dovrebbe
continuare e provare a trovare la corrispondenza con la sequenza
specificata:
(('0'..'9')('0'..'9')'/')(('0'..'9')('0'..'9')'/')('0'..'9')('0'..'9')
|
Se riesce a farlo allora il token riconosciuto sarà DOB,
come da regola originaria. Se il predicato sintattico fallisce e non si
trovano le due cifre seguite dallo slash allora il lexer dovrebbe
provare la regola specificata dalla prima alternativa, dopo la '|':
| ('0'..'9')+ { $setType(AGE); } ;
|
Ciò significa che se la regola scatta allora l'azione
specificata di seguito viene eseguita, ossia viene effettuata la
chiamata alla direttiva ANTLR $setType(type). Si noti che
questa non è una istruzione Java bensì di ANTLR ed è
prefissata da una '$'. È stato mostrato come un
predicato sintattico può disambiguare tra due regole che
iniziano con gli stessi caratteri.
WS :
(' '
| '\t'
| '\r' '\n' { newline(); }
| '\n' { newline(); }
)
{ $setType(Token.SKIP); }
;
|
La regola WS serve per la spaziatura (white
space da cui l'acronimo "WS"). La regola corrisponde al
caso della lettura di uno spazio (' ') OPPURE una tabulazione
('\t') OPPURE un ritorno-carrello seguito da un
carattere di nuova-linea (DOS '\r' '\n') OPPURE un
nuova-linea Unix ('\n') fatto di un solo carattere. Si noti
che le alternative per il nuova-linea DOS e Unix hanno azioni ad esse
associate; tali azioni sono chiamate al metodo newline() che
dice ad ANTLR di aggiornare il contatore di righe e andare a capo
sulla prossima linea. Senza di questo il lexer rimarrebbe piantato su
una stessa riga! Tutte le alternative sono raggruppate tra parentesi.
Esse hanno un'azione globale ad esse associata che serve a settare il
tipo di token al tipo speciale ANTLR di Token.SKIP che fa sì
che il token venga ignorato.
Questo serve semplicemente alla corrispondenza con il punto e
virgola (';').
Il lexer ed il parser sono innescati attraverso un metodo main.
Questo può essere incluso come blocco di codice nella sezione del
parser (o quella del lexer) nella forma di metodo static main
cosicché non ci si dovrebbe preoccupare di scrivere una classe
supplementare. Per chiarezza, mostreremo qui una classe
supplementare:
import java.io.*;
public class Main {
public static void main(String args[]) {
DataInputStream input = new DataInputStream(System.in);
SimpleLexer lexer = new SimpleLexer(input);
SimpleParser parser = new SimpleParser(lexer);
try {
parser.entry();
} catch(Exception e) {}
}
}
|
In breve, l'istanza di un flusso di input viene passata al
costruttore del lexer che a sua volta viene passato al costruttore
del parser. Una volta che il parser è stato creato, viene
invocato il metodo entry definito nel nostro parser
per fare tutto il lavoro. Questo è uno orientato a ricevere
l'input da un file mediante ridirezione ma si potrebbe benissimo
ricevere l'input dalla linea di comando, se il metodo main viene
invocato senza applicazione di ridirezione. Ecco il file test.txt
06/06/82 Peter 20;
03/04/83 Rosie 19;
04/05/81 Mikey 21;
|
Dopo aver creato le classi con:
java antlr.Tool Simple2.g
|
E compilando il tutto:
viene eseguita la classe Main:
che produce l'output:
Name: Peter, Age: 20, DOB: 06/06/82
Name: Rosie, Age: 19, DOB: 03/04/83
Name: Mikey, Age: 21, DOB: 04/05/81
|
Si può simulare un errore cambiando l'età di Mikey
in "a21", il che produce l'output:
Name: Peter, Age: 20, DOB: 06/06/82
Name: Rosie, Age: 19, DOB: 03/04/83
line 3: expecting AGE, found 'a'
|
8. Esempio di Valutazione di
Espressioni
È venuto il momento in cui è necessario imbattersi
nel classico esempio della valutazione di espressioni. La valutazione
delle espressioni viene introdotta in modo semplice per poi
aggiungere ulteriori caratteristiche. La grammatica ANTLR iniziale
per la valutazione di espressioni expression.g
viene di seguito mostrata:
class ExpressionParser extends Parser;
options { buildAST=true; }
expr : sumExpr SEMI!;
sumExpr : prodExpr ((PLUS^|MINUS^) prodExpr)* ;
prodExpr : powExpr ((MUL^|DIV^|MOD^) powExpr)* ;
powExpr : atom (POW^ atom)? ;
atom : INT ;
class ExpressionLexer extends Lexer;
PLUS : '+' ;
MINUS : '-' ;
MUL : '*' ;
DIV : '/' ;
MOD : '%' ;
POW : '^' ;
SEMI : ';' ;
protected DIGIT : '0'..'9' ;
INT : (DIGIT)+ ;
{import java.lang.Math;}
class ExpressionTreeWalker extends TreeParser;
expr returns [double r]
{ double a,b; r=0; }
: #(PLUS a=expr b=expr) { r=a+b; }
| #(MINUS a=expr b=expr) { r=a-b; }
| #(MUL a=expr b=expr) { r=a*b; }
| #(DIV a=expr b=expr) { r=a/b; }
| #(MOD a=expr b=expr) { r=a%b; }
| #(POW a=expr b=expr) { r=Math.pow(a,b); }
| i:INT { r=(double)Integer.parseInt(i.getText()); }
;
|
La definizione della grammatica inizia con la sezione del parser
che verrà spiegata passo per passo.
class ExpressionParser extends Parser;
options { buildAST=true; }
|
La classe viene dichiarata normalmente, poi si specifica l'opzione
buildAST=true che significa che il parser dovrebbe costruire
un AST (Abstract Syntax Tree) mentre analizza i token in
input. Una notazione speciale sarà usata per specificare come
costruire l'albero.
expr : sumExpr SEMI!;
sumExpr : prodExpr ((PLUS^|MINUS^) prodExpr)* ;
|
La regola principale dell'espressione è expr,
che serve solo a riferirsi al prossimo elemento nella gerarchia,
indicando che una expr può essere una
sumExpr. La regola specifica anche che l'espressione
termina con un token SEMI. Tale regola è
ridondante per il fatto che la regola principale poteva essere
direttamente costituita da quella di sumExpr poiché
expr si riferisce ad essa direttamente, con la sola
aggiunta di SEMI! (che altrimenti dovrebbe essere
aggiunto in coda a prodExpr). La ragione per tutto
ciò sta nel fatto che si rende più chiaro il fatto che
lo scopo generale è ricostruire un'espressione e non una
espressione additiva. Dopo SEMI di terminazione fa
da suffisso un '!', che dice al costruttore dell'AST di non
includere questo token nell'albero (come suffisso dell'intera
espressione).
La sumExpr è una espressione consistente
in una prodExpr seguita da zero o più
sequenze (PLUS OPPURE MINUS)
prodExpr, in modo che sumExpr possa
riconoscere sequenze come:
prodExpr
PLUS
prodExpr
MINUS
prodExpr
|
Poiché zero o più di queste sequenze devono essere
presenti perché si trovi la corrispondenza, si possono
costruire espressioni senza PLUS e MINUS
perché un'espressione può essere semplicemente una
prodExpr senza addizioni. Questa forma una gerarchia
dove a causa di questa opzionalità zero o più),
un'espressione può semplicemente essere un atom
che è un INT. Ciò verrà
spiegato più diffusamente più tardi.
Un AST è un tipo speciale di albero che può avere un
numero arbitrario di sottoalberi (figli) che sono a loro volta degli
AST. Attraversando l'albero si può accedere all'ordine nel
quale i nodi sono visitati con tutta l'espressività del
linguaggio di implementazione (Java, C++ or Sather).
I riferimenti a token PLUS e MINUS
sono seguiti da un carattere caret ('^'). Questa è
una direttiva ANTLR specifica per la creazione di AST: essa specifica
che il token contrassegnato dal caret deve diventare radice dell'AST
corrente o di un sottoalbero. Il primo token contrassegnato da caret
in una espressione da valutare diventerà la radice dell'AST
generale. Se un token contrassegnato viene incontrato mentre si
valuta il figlio di una radice, il figlio diventerà un nuovo
sottoalbero avente tale token come radice.
La struttura di AST è definita in modo tale da obbedire
alla precedenza degli operatori. In tal caso l'albero sarà
costruito in modo che la radice rappresenti un operatore e i figli
gli operandi. Quando un albero viene analizzato, lo sarà nella
maniera ordinaria, valutando i figli da sinistra verso destra
ricorsivamente. La regola:
sumExpr : prodExpr ((PLUS^|MINUS^) prodExpr)* ;
|
stabilisce che il primo e il secondo figlio di una sumExpr
devono essere delle prodExpr. È per questo
che la precedenza voluta viene garantita. Si veda la regola prodExpr:
prodExpr : powExpr ((MUL^|DIV^|MOD^) powExpr)* ;
|
Questa regola dice che una prodExpr deve
consistere in una powExpr seguita da zero o più
sequenze (MUL OPPURE DIV OPPURE MOD
E powExpr). La moltiplicazione, divisione e il
modulo sono stati raggruppati insieme perché hanno uguale
precedenza. Il caret ('^') viene usato ancora per
specificare che la radice di questa sequenza sarà l'operatore
specificato nell'espressione, quindi il primo e il secondo figlio
possono essere solo delle powExpr.
I figli della radice saranno valutati prima di applicarli alla
radice in tal modo le powExpr saranno valutate
prima, quindi il valore della powExpr saranno
calcolati prima di applicare l'operatore della prodExpr
il che rappresenta il corso di azioni desiderato dal momento che una
potenza ha una precedenza maggiore di un'espressione prodotto, che a
sua volta ha una precedenza più alta di una somma quindi
l'ordine di valutazione dell'espressione viene determinato dalla
struttura dell'AST creato che a sua volta forza le precedenze
desiderate.
powExpr : atom (POW^ atom)? ;
atom : INT ;
|
Si può vedere che una powExpr consiste in
un atomo seguito da una sequenza (POW atom).
Questo significa che la sequenza deve comparire zero o una volta.
Perché non definire come zero o più ripetizioni come
segue?
powExpr : atom (POW^ atom)* ;
|
Perché questa powExpr è difettosa.
Cosa succede se viene specificato più di un esponente?
L'ordine di valutazione avverrà da sinistra a destra ma
dovrebbe andare da destra verso sinistra (tra gli esponenti POW)
poiché un'espressione come 3^2^2 andrebbe valutata
come (3^(2^2)) mentre viene valutata come ((3^2)^2).
Un rimedio per questo caso sarà esaminato più tardi.
Consentendo al massimo una sola sequenza (POW atom),
questo problema non viene incontrato ma si limita l'utente ad un solo
livello di esponente. Dato che un esponente a più livelli è
lo stesso di un esponente uguale al prodotto degli esponenti, questo
non dovrebbe risultare un problema.
Il punto è che i sottoalberi devono essere valutati per
primi, così l'AST viene creato in modo che i sottoalberi di
AST che definiscono gli operatori di più alta precedenza sono
ammessi solo come figli di sottoalberi che definiscono operatori a
più bassa precedenza, pertanto l'operazione a più alta
precedenza viene sempre valutata per prima. Si può vedere che
la regola finale è destinata ad un atom che è
un INT. Perciò l'espressione più
semplice possibile sarà un singolo intero.
|
|
Nota
|
|
Potrebbe risultare più facile pensare all'AST
qui definito come un albero binario perché ognuno degli
operatori ha solo due figli; questo è più intuitivo
e forse più facile da capire. Effettivamente, per mantenere
l'analogia, i sottoalberi sinistro e destro della radice saranno
valutati prima di collegarli alla radice dell'albero, cioè
l'albero viene attraversato in postordine: sinistra, destra,
radice.
|
Guardiamo un'altra volta il parser in un unico listato:
class ExpressionParser extends Parser;
options { buildAST=true; }
expr : sumExpr SEMI!;
sumExpr : prodExpr ((PLUS^|MINUS^) prodExpr)* ;
prodExpr : powExpr ((MUL^|DIV^|MOD^) powExpr)* ;
powExpr : atom (POW^ atom)? ;
atom : INT ;
|
Come può un'espressione ridursi ad un solo atomo? Si assuma
di provare a trovare la corrispondenza con l'espressione "5;".
Essa consiste dei token INT e SEMI.
Il parser proverà a far corrispondere il token INT
con una delle sue regole. Guarda la rima regola, expr,
e vede che si fa riferimento alla sottoregola sumExpr,
per cui la prende in considerazione. La prima componente di sumExpr
è prodExpr per cui il parser prova a far
corrispondere il token con una prodExpr. La prima
componente di prodExpr è powExpr
per cui il parser prova la corrispondenza con questa sottoregola.
La prima componente di powExpr è un atom
per cui il parser prova a farlo corrispondere con il token. atom
è definita come consistente in un token INT
che è quanto il parser stava cercando per cui la
corrispondenza con atom va a buon fine, che è
quanto serviva alla regola powExpr ed a loro volta a
prodExpr, sumExpr fino alla prima
componente della regola per expr. Il prossimo token
su cui lavorare è SEMI che corrisponde alla
seconda componente di expr, pertanto questa regola
ha trovato la sua corrispondenza. ecco un diagramma che prova ad
illustrare tutto il processo:
Le linee rosse (o grigie se si è in modalità B/N),
servono a rappresentare corrispondenze non andate a buon fine mentre
le direzioni delle frecce mostrano l'ordine in cui il parser prova le
regole. Le linee verdi mostrano corrispondenze corrette. Tuttavia, la
linea da SEMI a SEMI rappresenta
un'eccezione, ed in verde perché s voleva mostrare che SEMI
ha portato ad una corrispondenza. Si suppone che la prima linea
uscente da INT non rappresenti davvero un fallimento
ma non si è voluto sovraccaricare il diagramma con altri
colori.
Queste regole gestiscono correttamente la precedenza ? Vediamo. Si
consideri l'espressione 1+2*5;. Sappiamo che essa andrebbe
valutata come (1+(2*5)) e non ((1+2)*5). Questo
corrisponde alla sequenza (INT)(PLUS)(INT)(MUL)(INT)(SEMI).
Il parser riesce a generare solo l'albero:
perché una sumExpr non può essere
sottoalbero di una prodExpr, come definito dalla
grammatica del parser. È a causa della struttura della
definizione che vengono stabilite le regole per la precedenza. Ecco
la versione AST dell'albero riportato sopra:
Un AST può avere un numero arbitrario di figli cui si fa riferimento col nome di fratelli (siblings). Si
può sviluppare l'albero come:
dove sum è una funzione che accetta una
lista di argomenti e restituisce la loro somma; naturalmente si
dovrebbe definire cosa fare incontrando un particolare nodo
dell'albero usando un treeparser (detto anche treewalker visto che
simula una passeggiata - walk - sull'albero). la successiva
sezione della grammatica è quella del lexer:
class ExpressionLexer extends Lexer;
PLUS : '+' ;
MINUS : '-' ;
MUL : '*' ;
DIV : '/' ;
MOD : '%' ;
POW : '^' ;
SEMI : ';' ;
protected DIGIT : '0'..'9' ;
INT : (DIGIT)+ ;
|
Queste regole sono abbastanza auto-esplicative e definiscono i
token usati nel parser appena descritto. Quella di DIGIT
è una regola protetta. Ciò significa che non vi si può
fare riferimento dall'esterno bensì solo da regole interne.
Viene usato nella definizione della regola per INT
che dice "una o più cifre". Se non veniva
specificato protected, ANTLR avrebbe generato un errore per
un caso di non-determinismo tra DIGIT e INT.
La successiva sezione della grammatica è quella del
tree-parser:
{import java.lang.Math;}
class ExpressionTreeWalker extends TreeParser;
expr returns [double r]
{ double a,b; r=0; }
: #(PLUS a=expr b=expr) { r=a+b; }
| #(MINUS a=expr b=expr) { r=a-b; }
| #(MUL a=expr b=expr) { r=a*b; }
| #(DIV a=expr b=expr) { r=a/b; }
| #(MOD a=expr b=expr) { r=a%b; }
| #(POW a=expr b=expr) { r=Math.pow(a,b); }
| i:INT { r=(double)Integer.parseInt(i.getText()); }
;
|
Le righe prima della dichiarazione della classe sono
un'intestazione che sarà ricopiata nel file Java generato
immediatamente prima della dichiarazione della classe. La spaziatura
tra le due graffe è significativa per cui non è stato
lasciato spazio, cosa non necessaria in quel punto. java.Math
viene importata per poter usare le sue classi. Dopo la
dichiarazione della classe viene la definizione della regola expr
a restituire la variabile r di tipo double:
expr returns [double r]
{ double a,b; r=0; }
|
Immediatamente prima dell'apertura della regola c'è una
sezione di codice Java che definisce due variabili double a
e b ed inizializza r a zero.
: #(PLUS a=expr b=expr) { r=a+b; }
| #(MINUS a=expr b=expr) { r=a-b; }
| #(MUL a=expr b=expr) { r=a*b; }
| #(DIV a=expr b=expr) { r=a/b; }
| #(MOD a=expr b=expr) { r=a%b; }
| #(POW a=expr b=expr) { r=Math.pow(a,b); }
| i:INT { r=(double)Integer.parseInt(i.getText()); }
;
|
Le definizioni delle regole fanno tutte riferimento alla sintassi
degli AST, cioè:
#(RADICE figlio.1 figlio.2 ... figlio.n);
|
La prima regola dice, se si trova PLUS come
radice, allora assegna i valori della valutazione dei due sottoalberi
figli alle variabili a e b, rispettivamente. La
regola non dice letteralmente "valuta i sottoalberi",
questo accade automaticamente per il fatto che la regola dice di
analizzare un albero con PLUS come radice che ha due
expr come suoi figli. Sarà nell'analizzare
tali figli che, per far scattare l'intera regola, i sottoalberi figli
verranno valutati. L'azione specificata in caso di corrispondenza
trovata comporta l'assegnazione del valore di a + b ad r.
In questo caso è ovvio, con un valore di lookahead ad uno,
che la regola da innescare se si trova un PLUS come
radice poiché questa è l'unica regola che ha questo
token come primo elemento. Ma potrebbe non essere sempre così.
Si consideri l'aggiunta della possibilità di indicare anche il
segno di un numero (per quante volte si vuole, ad es. -+-+-5)
quindi i token PLUS e MINUS non
sarebbero usati per operazioni binarie ma anche come primi elementi
di regole monadiche del segno. Con un lookahead di uno ci sarebbero
conflitti. Questo problema verrà ripreso più tardi.
| i:INT { r=(double)Integer.parseInt(i.getText()); }
|
Questa alternativa è più interessante delle altre
pertanto merita una menzione speciale. Semplicemente si assegna a r
il valore dell'INT trovato. Così, questo
serve a gestire il "caso base".
Il treeparser viene usato per attraversare l'albero e valutare le
espressioni inserite. Guardiamo come tutto questo possa funzionare.
Ecco il Main.java:
import java.io.*;
import antlr.CommonAST;
import antlr.collections.AST;
import antlr.debug.misc.ASTFrame;
public class Main {
public static void main(String args[]) {
try {
DataInputStream input = new DataInputStream(System.in);
ExpressionLexer lexer = new ExpressionLexer(input);
ExpressionParser parser = new ExpressionParser(lexer);
parser.expr();
CommonAST parseTree = (CommonAST)parser.getAST();
System.out.println(parseTree.toStringList());
ASTFrame frame = new ASTFrame("The tree", parseTree);
frame.setVisible(true);
ExpressionTreeWalker walker = new ExpressionTreeWalker();
double r = walker.expr(parseTree);
System.out.println("Value: "+r);
} catch(Exception e) { System.err.println("Exception: "+e); }
}
}
|
Prima di tutto si importano tutte le classi necessarie ed un
metodo static main apre la classe come al solito. I
contenuti del main sono racchiusi in un'istruzione
try...catch per catturare ogni eventuale errore generato. Se
ve ne sono, gli errori vengono stampati su stdout.
DataInputStream input = new DataInputStream(System.in);
|
Viene inizializzato un DataInputStream.
ExpressionLexer lexer = new ExpressionLexer(input);
|
Viene creato il lexer cui viene detto di accettare dati
dall'inputstream.
ExpressionParser parser = new ExpressionParser(lexer);
parser.expr();
|
Viene creato il parser usando il lexer per la ricezione dei token.
Si chiama il metodo expr() della classe che dice al parser
di cercare la corrispondenza con una espressione così come
definito dalle regole del parser.
CommonAST parseTree = (CommonAST)parser.getAST();
|
Si rammenti che era stato aggiunto options { buildAST=true; }.
Qui viene creato un oggetto CommonAST e gli viene assegnato
un riferimento all'AST creato dalla regola di parser expr.
Deve essere convertito a partire dalla superclasse collections.AST.
System.out.println(parseTree.toStringList());
|
L'AST viene stampato usando il metodo CommonAST
toStringList().
ASTFrame frame = new ASTFrame("The tree", parseTree);
frame.setVisible(true);
|
Un nuovo ASTFrame viene creato, cioè un frame
pensato per visualizzare AST importati da antlr.debug.misc.ASTFrame.
Il frame viene creato con il titolo "The tree" e
l'oggetto CommonAST creato prima. Il frame viene quindi reso
visibile. Questo genera un frame che mostra l'AST.
double r = walker.expr(parseTree);
System.out.println("Value: "+r);
|
Viene definito un nuovo double cui viene assegnato il
valore dell'espressione fornita dalla chiamata della regola expr
definita per il Treeparser creato (che si traduce in un metodo Java).
L'AST viene passato come parametro. Infine il valore dell'espressione
viene stampato sul stdout.
Seguiamo fino alla fine una espressione d'esempio per vedere che
output viene generato. Si assuma che tutte le classi sono state
generate dall'invocazione di ANTLR. L'espressione:
viene messa in un file chiamato test.txt ed usata come
input per Main:
L'albero espresso come lista attraverso toStringList()
viene restituito:
( - ( + 1 2 ) ( / ( * 3 4 ) ( ^ 5 6 ) ) ) ;
|
L'AST si vede con l'ASTFrame:
e il valore viene restituito:
Questo conclude il valutatore di espressioni semplici. La prossima
sezione illustrerà alcune estensioni.
9. Estensione della
Valutazione delle Espressioni
9.1.
Espressioni Annidate
Il vecchio valutatore non consentiva l'annidamento di parentesi.
In effetti le parentesi non erano affatto menzionate. Si provi a
pensare come si possano aggiungere parentesi annidate al valutatore.
Come si può dire al valutatore di creare un AST tale da
valutare prima le parentesi annidate più all'interno? La
soluzione è piuttosto semplice, forse un po' furba. Prima di
tutto vediamo il contenuto del parser:
expr : sumExpr SEMI;
sumExpr : prodExpr ((PLUS^|MINUS^) prodExpr)*;
prodExpr : powExpr ((MUL^|DIV^|MOD^) powExpr)* ;
powExpr : atom (POW^ atom)? ;
atom : INT ;
|
powExpr ha una precedenza superiore a quella di
prodExpr ed è reso figlio di una prodExpr
a causa della struttura ad albero. Durante l'attraversamento
dell'albero, i figli saranno valutati in modo indipendente dalla
radice poiché i valori della valutazione dei figli sono
assegnati alle variabili a e b prima che
l'operatore venga applicato e si restituisca il risultato:
#(PLUS a=expr b=expr) { r=a+b; }
|
Si osservi che a e b devono essere valutati
prima perché l'operazione viene eseguita soltanto dopo che la
regola è stata innescata con successo, il che significa che a
e b devono essere state valutate entrambe. La componente
primaria di questo AST è un atom. Si vuole
significare che un atomo può anche essere un'altra
espressione. Non si può semplicemente ridefinire atom
come:
questo genererebbe errori dovuti a ricorsione infinita:
expression.g:8: infinite recursion to rule sumExpr from rule atom
expression.g:7: infinite recursion to rule sumExpr from rule powExpr
expression.g:6: infinite recursion to rule sumExpr from rule prodExpr
expression.g:5: infinite recursion to rule sumExpr from rule sumExpr
expression.g:8: infinite recursion to rule sumExpr from rule atom
|
Si immagini il caso di un token fuori posto. Il parser
controllerebbe la presenza del token in tutte le regole e troverebbe
che non ci sarebbe corrispondenza, raggiungerebbe il fondo della
lista che si chiude con atom, e troverebbe che INT
non corrisponde, pertanto rimarrebbe la corrispondenza con expr
che farebbe ripartire il controllo attraverso tutte le regole e così
via, all'infinito. Pertanto expr deve essere
ridefinita come:
expr : LPAREN^ sumExpr RPAREN! ;
|
La ridefinizione è cruciale, LPAREN e
RPAREN sono token definiti nel lexer e rappresentano
'(' and ')' rispettivamente. Questa regola dice di
trovare LPAREN seguito da una sumExpr
seguita da RPAREN. LPAREN è
suffissato da un caret ('^') che indica che nell'AST
generato LPAREN dovrebbe diventare una radice di un
albero ed avere il figlio sumExpr, mentre RPAREN
non diventa un suo figlio perché è seguito da un punto
esclamativo. Ciò perché non è necessario all'AST
finale. Anche SEMI può essere rimosso dato
che espressioni annidate non devono essere terminate da un SEMI.
Se il token fuori posto si ripresentasse di nuovo, il parser non
potrebbe entrare in un ciclo infinito perché la regola expr
inizia con un token LPAREN, quindi se il token
trovato non corrisponde a LPAREN allora il parser
lancerebbe immediatamente una eccezione noViableAltException.
In nessun modo il token errato potrebbe superare la prova della
regola expr. Ecco la nuova definizione del parser in
un unico blocco:
expr : LPAREN^ sumExpr RPAREN! ;
sumExpr : prodExpr ((PLUS^|MINUS^) prodExpr)* ;
prodExpr : powExpr ((MUL^|DIV^|MOD^) powExpr)* ;
powExpr : atom (POW^ atom)? ;
atom : INT | expr ;
|
Così adesso una expr può contenere
ricorsivamente quante expr si vuole. Cosa dovrebbe
fare il treeparser quando incontra un albero o sottoalbero con LPAREN
come radice e expr come figlio ? L'azione desiderata
è restituire il valore della valutazione del figlio.
L'aggiunta di questa regola al treeparser lo consente:
| #(LPAREN a=expr) { r=a;}
|
Questa regola fa trovare nell'AST il token LPAREN
come radice ed una expr come figlio. Il risultato
della valutazione di expr viene assegnato alla
variabile a che a sua volta è assegnata alla
variabile r, quindi r non riceverà un valore
prima di a che a sua volta deve attendere la valutazione di
expr quando questa regola scatta. La valutazione di
tutti i sottoalberi di expr potrebbe comportare
dover valutare altre expr annidate.
Alla fine tutte le foglie dell'AST devono essere degli INT,
a meno che un numero infinito di sottoespressioni fosse contenuto
nell'espressione iniziale, il che risulta inverosimile. Si assume che
la persona che scrive l'espressione abbia abbastanza cervello da no
tentare di generare strane AST che continuino a chiamare expr
per miliardi di sottolivelli, per trovare la corrispondenza con
infiniti ordini di expr annidate allorché si
tenti di trovare la corrispondenza della expr
originale. Non siam sicuri nemmeno che sia effettivamente possibile.
In una situazione normale le chiamate a expr
restituiranno un valore finale di tutti queste foglie INT
usate nelle varie operazioni specificate nell'espressione. I valori
di queste operazioni serviranno a ricostruire risalendo i livelli
fino alla expr originaria, quando ad a sarà
assegnato il valore di expr, r prenderà
il valore di a e il suo valore viene restituito.
Per riassumere: quando si incontra un LPAREN, la
sub-espressione viene valutata; la valutazione della sub-espressione
restituirà il valore che sarà quindi usato nella
valutazione di expr che aveva la sotto-espressione
come figlia. La valutazione risultante potrebbe essere usata a sua
volta nella valutazione della expr madre fino a
quando nessun altra expr madre sia presente e la
expr originaria sia stata valutata.
Un AST che illustri questo fatto dovrebbe aiutare a chiarire le
cose. Ecco un AST dell'espressione (5*(2+3)):
La radice dell'albero è una expr denotata
dalla parentesi aperta LPAREN come atteso. Il suo
figlio è una prodExpr il cui primo figlio è
un atom che è un INT uguale
a cinque e il cui secondo figlio è un altro atom
ma questa volta una expr che ha come figlia una
prodExpr contenente due figli che sono entrambi atom
e sono INT uguali ai valori di due e tre
rispettivamente. Ecco un'altra illustrazione di questo AST che serve
a chiarire le cose:
Ecco la grammatica completa: expression2.g.
Il metodo main usato per eseguirlo è sempre quello
stesso usato per il valutatore dell'espressione originale.
|
|
Nota
|
|
Aggiungere sottoespressioni risolve anche il
problema di essere limitati da un singolo livello di esponente.
L'espressione ambigua (2^5^5) può essere riscritta
come (2^(5^)) per ottenere il risultato desiderato.
|
9.2. Aggiunta
dell'Operatore di Segno
L'operatore di segno ha una precedenza superiore ad ogni altro
operatore già definito in questo valutatore di espressioni,
quindi la sua regola comparirà giusto sopra quella di atom.
Non c'è bisogno di usare predicati sintattici per distinguere
tra l'uso binario ed unario degli operatori PLUS e
MINUS perché questo è implicato dal
contesto nel quale si usa l'espressione. Se si prova l'uso binario
degli operatori PLUS e MINUS il
parser si aspetterà di vedere l'operatore infisso tra due
prodExpr, mentre per l'uso unario il parser si
aspetterà l'operatone come prefisso di un atom.
ecco come si fa:
imaginaryTokenDefinitions :
SIGN_MINUS
SIGN_PLUS
;
expr : LPAREN^ sumExpr RPAREN! ;
sumExpr : prodExpr ((PLUS^|MINUS^) prodExpr)* ;
prodExpr : powExpr ((MUL^|DIV^|MOD^) powExpr)* ;
powExpr : signExpr (POW^ signExpr)? ;
signExpr : (
m:MINUS^ {#m.setType(SIGN_MINUS);}
| p:PLUS^ {#p.setType(SIGN_PLUS);}
)? atom ;
atom : INT | expr ;
|
Si ignori per ora il problema dei token immaginari. Sarà
spiegato in seguito.
Si consideri l'analisi dell'espressione (-3--2). Il primo
token è LPAREN che viene trovato durante la
valutazione di expr. Il secondo token è MINUS
per cui il parser controlla se il token possa essere una sumExpr
che risulta la prima regola da provare nella valutazione di expr.
MINUS è il primo token di sumExpr
? No, è una sottoregola per cui si prova prima prodExpr
per vedere se il primo token di quella regola è MINUS.
MINUS è il primo token di prodExpr
? No, è una sottoregola per cui si prova prima powExpr
per vedere se il primo token di quella regola è MINUS.
MINUS è il primo token di powExpr
? No, è una sottoregola per cui si prova prima signExpr
per vedere se il primo token di quella regola è MINUS.
MINUS è il primo token di signExpr
? Sì lo è! Benissimo, ma il MINUS deve
essere seguito da un atom per soddisfare signExpr.
Il successivo token è INT (3) quindi
alla fine qualche corrispondenza è stata trovata, in
particolare un signExpr. Un attimo, non facciamoci
fuorviare ora. Tutto questo processo è sorto dal fatto che il
parser cercava il primo token utile per la regola di sumExpr
perchè il suo genitore expr deve contenerne
uno. Questo ha causato chiamate a tutte le sottoregole fino a quella
di signExpr. Ora che una corrispondenza possibile è
stata determinata, il parser torna indietro su per i livelli di
ricorsione e scopre che ha soddisfatto powExpr
perché questo può consistere anche solo di una
signExpr, ma allora scopre di aver soddisfatto anche
una sumExpr che consiste anche di un'unica prodExpr.
In effetti si è quasi trovata una expr poiché
se il prossimo token risulta RPAREN allora avrebbe
finito. Tuttavia, la regola di sumExpr potrebbe non
essere terminata per cui il parser deve prima verificare se il
prossimo token sia compatibile con il prossimo token della sumExpr.
sumExpr : prodExpr ((PLUS^|MINUS^) prodExpr)* ;
|
Il prossimo token della regola è sumExpr
PLUS OPPURE MINUS mentre il
prossimo nell'espressione da analizzare è MINUS,
per cui si considera corrispondente il MINUS nella
prodExpr. Non c'è pericolo di ambiguità
qui perchè signExpr non è
un'alternativa a questo punto. Non c'è nessuna regola del tipo
(prodExpr signExpr)
pertanto sumExpr rappresenta l'unica strada. Se non
viene trovata una sumExpr allora nemmeno la expr
sarà ritrovata (poichè expr si
aspetterebbe una RPAREN) e la regola per
l'espressione fallirebbe. Il parser finirà di verificare se
questa regola sia applicabile prima di intraprendere ogni altra
azione, perciò anche se ci fosse una regola del tipo (prodExpr
signExpr) (da qualche altra parte nel parser),
sumExpr dovrebbe fallire prima di poter verificare
questa eventuale alternativa. Non c'è un'altra regola per cui
il parser usa la corrispondenza con MINUS in sumExpr
e la regola sumExpr va avanti come ci si aspettava.
Il parser ha giusto trovato la corrispondenza di MINUS
in sumExpr. Adesso prova a verificare prodExpr
che rappresenta la tera componente di sumExpr.
prodExpr viene riscontrato esattamente alla stessa
maniera del primo prodExpr. Questo significa che
sumExpr è stato riscontrato ed il parser ha
utilizzato anche il secondo token di expr. Il parser
ora si aspetta dal lexer un RPAREN, che arriva, per
cui expr viene riscontrata con successo. Ecco una
illustrazione
dell'intero processo
Speriamo di non aver reso poco chiaro il lavoro di questa regola.
Guardiamo più da vicino il suo operato:
signExpr : (
m:MINUS^ {#m.setType(SIGN_MINUS);}
| p:PLUS^ {#p.setType(SIGN_PLUS);}
)? atom ;
|
Prima di tutto si noti che la prima parte di signExpr
è racchiusa tra parentesi seguite da un punto interrogativo
indicante che una signExpr può essere o un
atom oppure un simbolo di segno seguito da un atomo.
La regola dice che se si incontra un MINUS o un PLUS
essi diventano la radice di un nuovo sottoalbero con atom
come unico figlio. Questo è esattamente il comportamento
desiderato dato che rendendo atom un figlio,
possiamo riconoscere la radice dell' albero del treeparser ed
eseguire qualche azione su questo figlio. Questo è il momento
in cui entrano in gioco i token immaginari:
assegna alla variabile m il nodo radice MINUS
{#m.setType(SIGN_MINUS);}
|
sostituisce nell'albero questo nodo radice con il token SIGN_MINUS
invece di MINUS. Questo si fa perché l'albero
usa già la radice MINUS per riconoscere che
si dovrebbe effettuare una operazione binaria di sottrazione:
| #(MINUS a=expr b=expr) { r=a-b; }
|
Per non dover avere qualche tipo di predicati sintattici per
determinare che tipo di operazione MINUS eseguire,
viene creato un altro token, chiamato SIGN_MINUS,
per rappresentare l'operazione unaria MINUS. La
stessa cosa si fa per l'operatore PLUS:
imaginaryTokenDefinitions :
SIGN_MINUS
SIGN_PLUS
;
|
analizzando l'AST, il tree-parser sa esattamente che tipo di
operazione effettuare. L'intera sezione del tree-parser è
mostrata di seguito:
{import java.lang.Math;}
class ExpressionTreeWalker extends TreeParser;
expr returns [double r]
{ double a,b; r=0; }
: #(PLUS a=expr b=expr) { r=a+b; }
| #(MINUS a=expr b=expr) { r=a-b; }
| #(MUL a=expr b=expr) { r=a*b; }
| #(DIV a=expr b=expr) { r=a/b; }
| #(MOD a=expr b=expr) { r=a%b; }
| #(POW a=expr b=expr) { r=Math.pow(a,b); }
| #(LPAREN a=expr) { r=a; }
| #(SIGN_MINUS a=expr) { r=-1*a; }
| #(SIGN_PLUS a=expr) { if(a<0)r=0-a; else r=a; }
| i:INT { r=(double)Integer.parseInt(i.getText()); }
;
|
Se si incontra una radice SIGN_MINUS la
conseguenza desiderata sarebbe di negare il segno dell'operando,
questo si ottiene moltiplicando l'operando per -1. Se si incontra una
radice SIGN_PLUS la conseguenza desiderata sarebbe
di non fare nulla se l'operando è già positivo e
rendere l'operando positivo se esso è negativo. Questo si
ottiene con un'istruzione condizionale che sottrae l'operando da zero
se esso è negativo e non fa niente all'operando altrimenti.
L'intera grammatica può essere trovata qui:
expression3.g.
Il metodo main usato per farlo girare è lo
stesso del valutatore di espressioni originario.
Guardiamo un esempio completo di esecuzione per l' espressione
(-3--2). Si assume che ANTLR sia stato eseguito su una
grammatica, tutte le classi sono compilate e l'espressione data in
ingresso al lexer tramite il main. Ecco la
stringList e il valore stampato:
( ( ( - ( - 3 ) ( - 2 ) ) )
Value: -1.0
|
Ecco l'AST prodotto:
Ecco alcuni altri AST:
|
|
Nota
|
|
Nel parser la valutazione di espressioni, una
espressione al livello principale è stata specificata come:
|
|
expr : LPAREN^ sumExpr RPAREN! ;
|
|
Se stessimo leggendo da un file, la regola dovrebbe
essere in realtà:
|
|
expr : LPAREN^ sumExpr RPAREN! EOF! ;
|
|
|
Affinché venga trovata la corrispondenza con
il EOF (End Of File) e l' intera regola scatti,
il parser cercherà comunque di trovare quante più
corrispondenze può, così da costruire l'AST.
L'inclusione di EOF nella regola non
permetterebbe di immettere espressioni sulla linea di comando a
meno di non avere la maniera per specificare direttamente il
carattere EOF. Si tenga a mente questa nota nella
costruzione di parser che leggono da file.
|
10. Un Esempio di
Traduzione: da CSV ad una Tabella XHTML
Un lexer traduce da un flusso di caratteri ad un flusso di token.
Un parser riconosce certe sequenze di token ed esegue azioni basate
su questo riconoscimento come ad esempio convertire la sequenza in
istruzioni di linguaggio macchina da eseguire più tardi, o
anche generare un AST per una futura visita. La più consueta
delle due cose sarebbe di generare dapprima un AST - un'altra
traduzione - e poi analizzare questo AST per generare dell'altra
forma di output. La compilazione può essere considerata come
una serie di traduzioni: questa sezione illustrerà l'idea
della traduzione con un semplice esempio che traduce un file CSV
(comma separated variable) in una tabella XHTML.
Una CSV è un tipo molto semplice di struttura dati:
variabili separate da virgole e ritorni a capo per creare un tipo di
tabella. Un esempio chiarifica il tutto:
"STUDENT ID, "NAME, "DATE OF BIRTH
"129384, "Davy Jones, "03/04/81
"328649, "Clare Manstead, "30/11/81
"237090, "Richard Stoppit, "22/06/82
"523343, "Brian Hardwick, "15/11/81
"908423, "Sally Brush, "06/06/81
"328453, "Elisa Strudel, "12/09/82
"883632, "Peter Smith, "03/05/83
"542033, "Ryan Alcot, "04/12/80
|
Il traduttore sviluppato in questa sezione tradurrà CSV di
questo tipo. La struttura del CSV sarà illustrata nel mentre
che si sviluppa il parser. Questo mostrerà la primissima forma
di traduzione, quella dalle idee generali circa la struttura del file
in un parser ANTLR capaci di riconoscere questa struttura.
Il file CSV è composto da una o più
line e termina con un token EOF:
file : ( line (NEWLINE line)* (NEWLINE)? EOF )
|
Una line consiste di una o più record.
NEWLINE viene gestito da file.
Un record consiste in un token RECORD, seguito opzionalmente da un token COMMA (perché i token alla fine di una riga o di un file non sono seguiti da un COMMA):
record : ( (r:RECORD) (COMMA)? ) ;
|
Si noti che l'ultima riga del CSV è un caso eccezionale
perché termina con un EOF invece di un
NEWLINE. Questo viene gestito tramite la regola file
la quale dice che un file inizia con una riga, ha zero o più
sequenze (NEWLINE line) quindi ha un NEWLINE
opzionale e poi alla fine termina con un token EOF.
class CSVParser extends Parser;
file : ( line (NEWLINE line)* (NEWLINE)? EOF )
line : ( (record)+ ) ;
record : ( (r:RECORD) (COMMA)? ) ;
|
È accoppiato con questo lexer:
class CSVLexer extends Lexer;
options { charVocabulary='\3'..'\377'; }
RECORD : '"'! (~(','|'\r'|'\n'))+ ;
COMMA : ',' ;
NEWLINE : ('\r''\n')=> '\r''\n' //DOS
| '\r' //MAC
| '\n' //UNIX
{ newline(); }
;
WS : (' '|'\t') { $setType(Token.SKIP); } ;
|
Prima di tutto, charVocabulary viene posta a
'\3'..'\377', questo definisce un insieme di caratteri
Unicode al quale i caratteri nel flusso di input devono appartenere.
Esso definisce anche implicitamente quali caratteri saranno usati
come alternative quando si specifica un tipo di regola "tutto
tranne ...".
RECORD è un esempio di una regola "tutto
tranne ..." e dice che un RECORD consiste in
uno o più caratteri nell'intervallo di caratteri definito,
tranne la virgola, il ritorno-carrello e il nuova-linea. Si noti che
RECORD è stato definito come iniziante con un
carattere di doppio apice; questo formato è stato scelto
perché l' utente possa includere con facilità record
con spazi all'interno. Se non si fosse usato questo doppio apice per indicare l'inizio del record, esso consisterebbe di tutti i
caratteri dall'inizio del record fino alla prossima virgola, il che
comprenderebbe anche gli spazi. Se si usasse un CSV bene allineato come:
Dave, 21
Richard, 55
Peter, 98
allora i record sarebbero "Dave", " 21"
poi "Richard", "55 ",
"Peter" e " 98"
che probabilmente non è il risultato desiderato.
Naturalmente si potrebbe elaborare i token successivamente per
eliminare gli spazi all'inizio ed alla fine, ma allora cosa succederebbe se uno dei
token dovesse contenere spazi all'inizio o alla fine ? Si è deciso che in questo esempio i record sarebbero definiti nel modo seguente. Si può cambiare a piacimento queste decisioni di
progetto per imparare facendo esperienza. Una cosa ulteriore da
notare su questo tema è che i doppi apici sono seguiti da un
punto esclamativo affinché lo stesso doppio apice non venga
incluso nel testo del token vero e proprio. Le restanti regole del
lexer sono auto-esplicative.
Se questi lexer e parser fossero usati per elaborare un file CSV,
non niente succederebbe tranne che le regole scatterebbero correttamente
e il programma terminerebbe con uno stato d'uscita pari a zero. A
scopo esemplificativo, sono state aggiunte istruzioni di stampa di
quando una regola viene chiamata e se ha riscontrato la stringa
cercata e di che record si trattava:
class CSVParser extends Parser;
options { k=2; }
file {System.out.println("file called");}
: ( line (NEWLINE line)* (NEWLINE)? EOF)
{System.out.println("file matched");}
;
line {System.out.println("line called");}
: ( (record)+ )
{System.out.println("line matched");}
;
record {System.out.println("record called");}
: ( (r:RECORD) (COMMA)? )
{System.out.println("record = " + r.getText());
System.out.println("record matched");}
;
|
Si noti il lookahead di due per distinguere tra (NEWLINE
line) e (NEWLINE) EOF. Il parser è
stato eseguito (attraverso il metodo main spiegato più
tardi), sul file seguente:
"David Sprocket, "89
"Cindy Brocket, "18
"Michael Rocket, "33
|
L'output che veniva prodotto è mostrato di seguito (
riformattato a mano per maggiore chiarezza):
file called
line called
record called
record = David Sprocket
record matched
record called
record = 89
record matched
line matched
line called
record called
record = Cindy Brocket
record matched
record called
record = 18
record matched
line matched
line called
record called
record = Michael Rocket
record matched
record called
record = 33
record matched
line matched
file matched
|
La grammatica ANTLR realizzata fino ad ora può essere
scaricata qui: csv1.g. È
abbastanza ovvio dall'output che il parser funziona a dovere. Per
produrre una tabella HTML, si devono solo cambiare le istruzioni di
output affinché invece di emettere il messaggio file
called, o qualunque altra cosa, restituisce invece <table>
o qualsivoglia debba essere l'equivalente codice HTML. Il parser, modificato
per emettere istruzioni HTML è mostrato di seguito:
class CSVParser extends Parser;
options { k=2; }
file {System.out.println("<table align=\"center\" border=\"1\">");}
: ( line (NEWLINE line)* (NEWLINE)? EOF)
{System.out.println("</table>");}
;
line {System.out.println(" <tr>");}
: ( (record)+ )
{System.out.println(" </tr>");}
;
record {System.out.print(" <td>");}
: ( (r:RECORD) (COMMA)? )
{System.out.print(r.getText());
System.out.println("</td>");}
;
|
L'output prodotto durante l'elaborazione dello stesso file di
prima è:
<table align="center" border="1">
<tr>
<td>David Sprocket</td>
<td>89</td>
<tr/>
<tr>
<td>Cindy Brocket</td>
<td>18</td>
<tr/>
<tr>
<td>Michael Rocket</td>
<td>33</td>
<tr/>
</table>
|
che è quanto si intendeva ottenere dal traduttore. A parte
modificare qua e là come dovrebbe apparire l'output quello di
cui abbiamo bisogno ora è emettere il resto del file HTML. La
generazione del resto del file potrebbe essere fatta nel parser
aggiungendo di più alla regola file ma questo
complicherebbe il parser. Invece, attribuiamo questo compito alla
classe che implementa parser e lexer. Un metodo main
potrebbe essere messo nella sezione parser della grammatica affinché,
quando il parser viene generato, ha un metodo main che può
essere eseguito. Alternativamente si potrebbe creare una classe
separata che ha un metodo main che implementa il traduttore.
Questo esempio userà una classe separata. Eccola:
import java.io.*;
public class Main {
public static void main(String args[]) {
if(args.length==0) { error(); }
FileInputStream fileInput = null;
try {
fileInput = new FileInputStream(args[0]);
} catch(Exception e) { error(); }
try {
DataInputStream input = new DataInputStream(fileInput);
CSVLexer csvLexer = new CSVLexer(input);
CSVParser csvParser = new CSVParser(csvLexer);
csvParser.file();
} catch(Exception e) { System.err.println(e.getMessage()); }
}
private static void error() {
System.out.println("*-----------------------*");
System.out.println("| USAGE: |");
System.out.println("| java Main inputfile |");
System.out.println("*-----------------------*");
System.exit(0);
}
}
|
Il programma dapprima controlla che venga fornito l'unico
argomento obbligatorio sulla linea di comando. Se non lo è
stato, il programma stampa un errore ed termina. Se lo è
stato, il programma crea un nuovo FileInputStream dal file
specificato. Se ci sono errori, viene stampato l'errore e il
programma termina. Se non ci sono errori il programma entra in un
altro blocco try dove un DataInputStream è
inizializzato a partire dal file, il lexer viene creato con questo
flusso, il parser viene creato a partire da questo lexer e quindi il
metodo file del parser. Se ci sono stati lanci di
eccezioni, esse sono catturate e viene stampato il messaggio
associato.
Il programma Main usato per eseguire il traduttore
può essere scaricato qui: Main.java.
L'intero file di grammatica può essere scaricato qui:
csv2.g.
Alcuni dati di test possono essere scaricati qui: test.txt
Al momento il parser fornisce l'output su stdout, questo
non è molto utile. Sarebbe più utile se il parser
restituisse una stringa dell'output HTML affinché la classe
chiamante possa fare con esso qualunque cosa voglia, come inviare
l'output su file. Il parser deve essere modificato per restituire una
stringa:
class CSVParser extends Parser;
options { k=2; }
file returns[String table = new String()]
{String lineData; table+="<table align=\"center\" border=\"1\">\n"; }
: ( lineData=line {table+=lineData;}
(NEWLINE lineData=line {table+=lineData;} )*
(NEWLINE)? EOF )
{table+="</table>";}
;
line returns [String lineData = new String()]
{String recordData; lineData+=" <tr>\n";}
: ( (recordData=record {lineData+=recordData;})+ )
{lineData+=" <tr/>\n";}
;
record returns [String recordData = new String()]
{recordData+=(" <td>");}
: ( (rec:RECORD) (COMMA)? )
{recordData+=(rec.getText());
recordData+="</td>\n";}
;
|
La grammatica completa può essere scaricata qui: csv3.g.
All'interno di file: immediatamente viene
concatenato l'elemento table alla var. String table
definita nella regola file. La prima riga viene
riscontrata e il valore ritornato viene assegnato alla variabile
lineData che viene a sua volta concatenata a table.
Vengono trovate zero o più righe e, durante il processo, i
valori restituiti dalla chiamata a line per
riscontrare ogni riga vengono assegnati alla variabile lineData
che viene concatenata a table.
line returns [String lineData = new String()]
{String recordData; lineData+=" <tr>\n";}
: ( (recordData=record {lineData+=recordData;})+ )
{lineData+=" <tr/>\n";}
;
|
All'interno di line: l'elemento iniziale <tr>
viene immediatamente concatenato alla variabile lineData.
Uno o più record vengono riscontrati ed ogni volta il valore
restituito dalla chiamata a record riscontrando un
record viene assegnato alla variabile recordData che viene
concatenata a sua volta a lineData.
record returns [String recordData = new String()]
{recordData+=(" <td>");}
: ( (rec:RECORD) (COMMA)? )
{recordData+=(rec.getText());
recordData+="</td>\n";}
;
|
All'interno di record: l'elemento di apertura td
viene concatenato alla stringa recordData. Un token RECORD
viene ritrovato e assegnati alla variabile rec. Il suo
contenuto testuale viene concatenato a recordData e alla
fine anche la chiusura </td>. Il record completo nella
forma di recordData viene restituito a line.
line riceve recordData e qeusta viene
usata nella costruzione di lineData. Quando tutti i record
in una riga sono ritrovati l'elemento di chiusura </tr>
viene concatenato a lineData e lineData viene
restituito.
file riceve lineData che viene usato
nella costruzione di table. Quando tutte le righe del file
sono state riscontrate il tag di chiusura </table>
viene concatenato a table e table restituito alla
classe che ha istanziato il parser.
Ecco la classe contenente il nuovo metodo main:
import java.io.*;
public class CSVhtml {
public static void main(String args[]) {
if(args.length!=2) { error(); }
FileInputStream fileInput = null;
DataOutputStream fileOutput = null;
try {
fileInput = new FileInputStream(args[0]);
fileOutput = new DataOutputStream(new FileOutputStream(args[1]));
} catch(Exception e) { error2(); }
try {
DataInputStream input = new DataInputStream(fileInput);
CSVLexer csvLexer = new CSVLexer(input);
CSVParser csvParser = new CSVParser(csvLexer);
String p ="";
p ="<?xml version=\"1.0\" encoding=\"utf-8\"?>\n";
p+="<!DOCTYPE html\n";
p+="PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\"\n";
p+="\"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\">\n";
p+="<html>\n";
p+=" <head>\n";
p+=" <title>A Table</title>\n";
p+=" <meta http-equiv=\"Content-Type\" content=\"text/html; charset=utf-8\"/>\n";
p+=" </head>\n";
p+=" <body>\n";
p+= csvParser.file();
p+=" </body>\n";
p+="</html>";
fileOutput.writeBytes(p);
fileOutput.close();
} catch(Exception e) { System.err.println(e.getMessage()); }
}
private static void error() {
System.out.println("*-------------------------------------*");
System.out.println("| USAGE: |");
System.out.println("| java CSVhtml inputfile outputfile |");
System.out.println("*-------------------------------------*");
System.exit(0);
}
private static void error2() {
System.out.println("*------------------------------------*");
System.out.println("| You must specify a valid inputfile |");
System.out.println("*------------------------------------*");
System.exit(0);
}
}
|
Il programma mostrato qui sopra può essere scaricato da:
CSVHTML.java. Il programma lavora
così: Si controlla che vi siano parametri passati dalla linea
di comando. Se ce ne sono si crea un DataInputStream per il
file di input che è specificato come primo parametro e si crea
un DataOutputStream per il file di output specificato come
secondo parametro sulla linea di comando. Vengono creati lexer e
parser. La stringa restituita dalla chiamata del metodo file
del parser viene concatenata a questa stringa. La chiusura HTML viene
concatenata alla stringa e questa viene inviata al file di output
passato.
Dopo che la grammatica è stata convertita da un lexer,
analizzata da ANTLR e tutto è stato compilato, il programma
può essere eseguito così:
java CSVHTML inputfile outputfile
|
La tabella prodotta dall'esecuzione del comando:
java CSVHTML test.txt output.html
|
In un certo browser web proprietario, appare come segue:
11.
Estratti da dietro le Quinte
Quando il lexer tokenizza il flusso di input, ogni token
incontrato viene categorizzato secondo il suo tipo, come ad esempio
NEWLINE. Viene creata una tabella di questi tipi di
token e ogni tipo di token è rappresentato da un intero. Gli
interi 1-3 sono speciali per il fatto che essi denotano tipi
predefiniti; Ai token definiti dall'utente sono assegnati interi che
li rappresentano a partire da 4. Gli interi vengono mappati
su identificatori leggibili per gli uomini in un file di tipi di
token generato da ANTLR, per esempio:
// $ANTLR 2.7.1: "csv.g" -> "CSVParser.java"$
public interface CSVParserTokenTypes {
int EOF = 1;
int NULL_TREE_LOOKAHEAD = 3;
int NEWLINE = 4;
int RECORD = 5;
int COMMA = 6;
int WS = 7;
}
|
C'è una classe detta TokenBuffer il cui lavoro è
di bufferizzare i token forniti dal lexer. Essa contiene un metodo
chiamato LA con un parametro intero che determina i token
nel buffer dei token da restituire. Per esempio: LA(1)
restituirebbe il valore intero del prossimo token nel TokenBuffer.
Il parser utilizza una serie di chiamate a LA per cercare la
corrispondenza con le regole che implementa, ad esempio:
// Note, I have cleaned this up a little, ANTLR generates things like
// { {instructions} {instructions} } which can be represented as
// { instructions instructions }
public final void file() throws RecognitionException, TokenStreamException {
try { // for error handling
System.out.println("file called");
int _cnt3=0;
_loop3:
do {
if ((LA(1)==RECORD)) {
line();
} else {
if ( _cnt3>=1 ) { break _loop3; }
else {throw new NoViableAltException(LT(1), getFilename());}
}
_cnt3++;
} while (true);
} catch (RecognitionException ex) {
reportError(ex);
consume();
consumeUntil(_tokenSet_0);
}
|
TokenBuffer fornisce token mediante LT e token
mediante LA. TokenBuffer riceve i suoi token per
conservarli nel buffer chiamando nextToken che è
definito nel lexer. Il metodo nextToken del lexer generato
per il traduttore di CSV è del tipo:
// Cleaned up a little by me
public Token nextToken() throws TokenStreamException {
Token theRetToken=null;
tryAgain:
for (;;) {
Token _token = null;
int _ttype = Token.INVALID_TYPE;
resetText();
try { // for char stream error handling
try { // for lexical error handling
switch ( LA(1)) {
case ',': {
mCOMMA(true);
theRetToken=_returnToken;
break;
}
case '\n': case '\r': {
mNEWLINE(true);
theRetToken=_returnToken;
break;
}
case '\t': case ' ': {
mWS(true);
theRetToken=_returnToken;
break;
}
default:
if ((_tokenSet_0.member(LA(1)))) {
mRECORD(true);
theRetToken=_returnToken;
} else {
if (LA(1)==EOF_CHAR) {uponEOF(); _returnToken = makeToken(Token.EOF_TYPE);}
else {throw new NoViableAltForCharException((char)LA(1), getFilename(), getLine());}
}
}
if ( _returnToken==null ) continue tryAgain; // found SKIP token
_ttype = _returnToken.getType();
_ttype = testLiteralsTable(_ttype);
_returnToken.setType(_ttype);
return _returnToken;
} catch (RecognitionException e) {
throw new TokenStreamRecognitionException(e);
}
} catch (CharStreamException cse) {
if ( cse instanceof CharStreamIOException ) {
throw new TokenStreamIOException(((CharStreamIOException)cse).io);
} else {
throw new TokenStreamException(cse.getMessage());
}
}
}
}
|
Si noti il pezzo che dice:
if (LA(1)==EOF_CHAR) {uponEOF(); _returnToken = makeToken(Token.EOF_TYPE);}
else {throw new NoViableAltForCharException((char)LA(1), getFilename(), getLine());}
|
Questo dice che se il token trovato è un EOF_CHAR,
chiama il metodo uponEOF ed assegna un nuovo token EOF_TYPE
a _returnToken, che viene restituito più tardi in
questo metodo.
Il codice qui sotto mostra che si assegna a rec il token
ritornato da LT. Più tardi viene invocato il metodo
getText() su rec per ottenere il contenuto testuale
del token.
{
rec = LT(1);
match(RECORD);
}
.
.
.
recordData+=(rec.getText());
recordData+="</td>\n";
|
12. Ringraziamenti
Grazie a Bogdan Mitu e Ric Klaren.
13. Riferimenti (e Link
Utili)
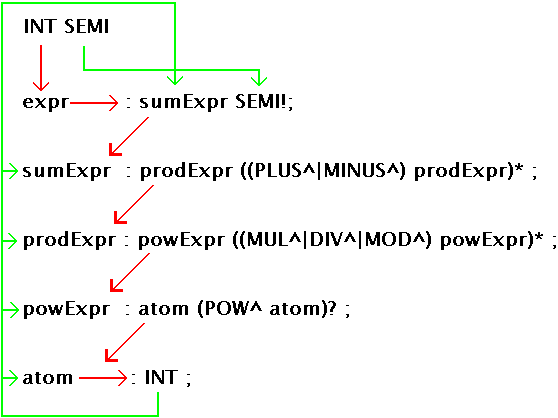
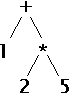
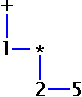
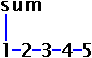
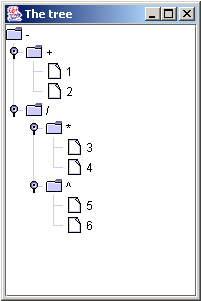
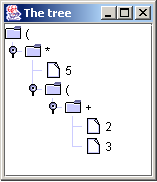
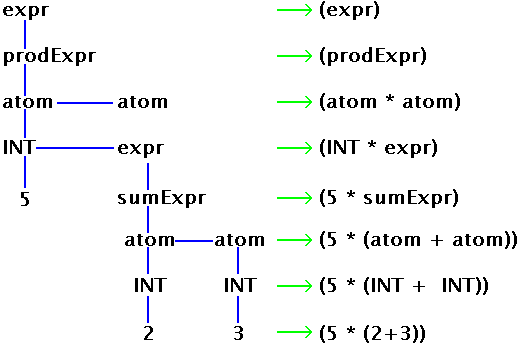
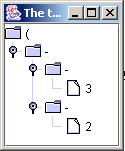
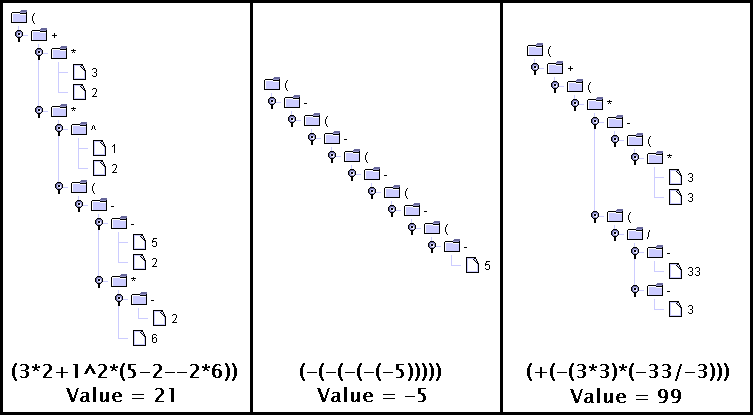
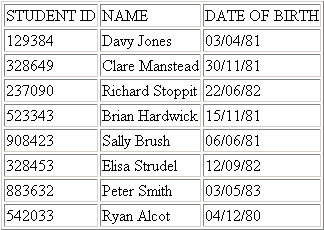
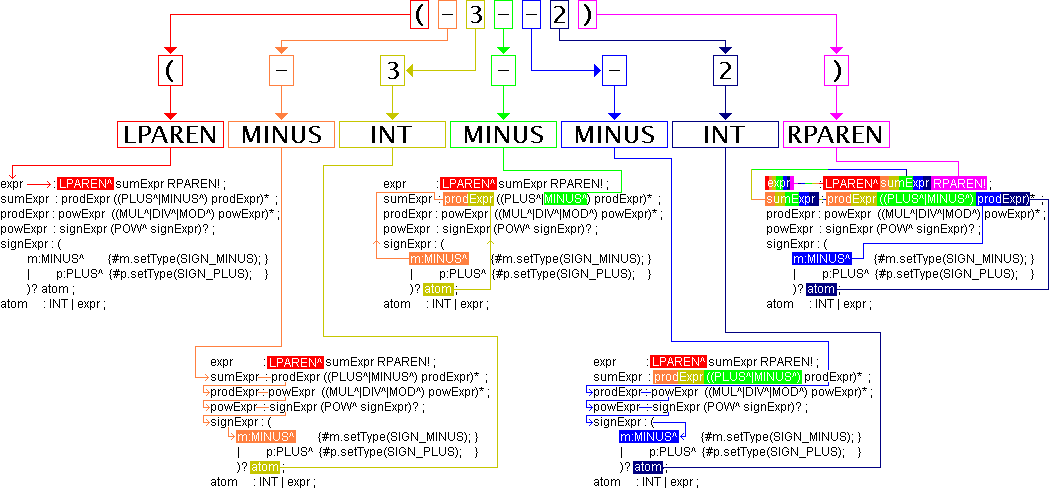{kind=link}