BEE is a system developed for the automatic annotation of biomedical texts. Implemented methods for tagging are general and domain-dependency is limited to specific thesauri of the biomedical domain. Additional domain specific knowledge is automatically acquired through an Inductive Logic Programming system (ATRE) that works on logical representations of the textual content. Text is preprocessed by means of ANNIE, a component of the GATE (General Architecture for Text Engineering) infrastructure for information extraction. JAPE (a Java Annotation Patterns Engine) language, which is available in GATE, is also used to recognize regular expressions.
BEE supports users in:
defining user annotation classes;
manually annotating texts to provide mining examples for user classes;
customizing linguistic analysis through dictionary (gazeteers) management;
automatically generating data for mining;
using induced models to perform automatic annotation of new texts;
The architecture of the BEE system is based on three main layers: data acquisition/persistence, text processing and text annotation. Data can be loaded from both file system and database. The text processing layer includes functionalities for text segmentation, text cleaning and normalization, feature extraction (statistical, morphological, lexical, semantical, structural features) and generation of logic descriptions for learning tasks. To perform feature extraction operations BEE exploits language engeneering modules of the GATE framework. The annotation layer allows final users to provide learning examples and expert users to manage learning processes in order to obtain a suitable knowledge base for automatic annotation tasks. Persistence of annotation results and learning operations is supported.
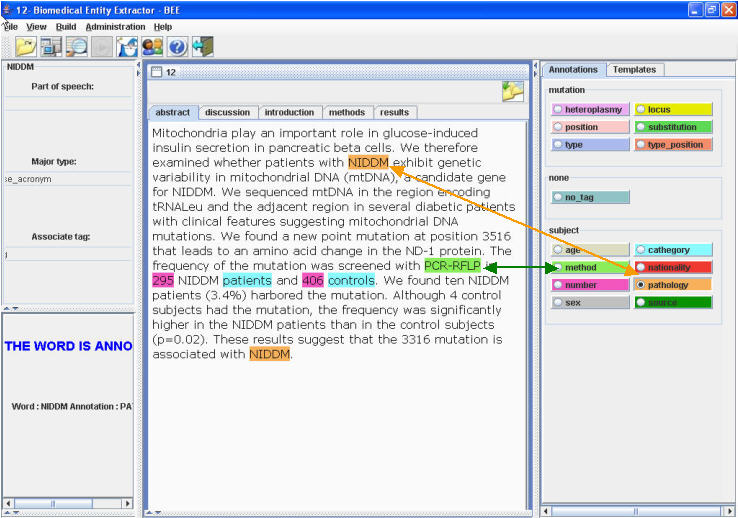
This application concerns the annotation of the HmtDB resource of variability and clinical data associated to mitochondrial pathological phenotypes. These data are prevalently available in the literature where are reported in a completely free style. In this scenario, the goal is to identify occurrences of specific biological objects (i.e., mutations) and their features (e.g., position in the DNA, involved nucleotides, etc.) as well as the method of analysis and some information on the subjects from which the DNA was extracted (e.g., age, gender, nationality, pathologies of the sample, etc.). This problem is translated in an information extraction problem. More precisely, the user is asked to define sets of annotation classes and to manually annotate data sets of interest. Domain dictionaries can be imported in the system to support text processing operations. Management of learning sessions is delegated to the expert user who can set parameters and launch experiments by using the BEE interface. Learned rules are used to automatically annotate new texts. The result of automatic annotation is visually proposed to the user who supervises and corrects annotations in order to allow the learner to improve the perfomances.
In the figure a tailoring of the BEE interface for this annotation task is reported.
M. Berardi, D. Malerba (2006). Learning Recursive Patterns for Biomedical Information Extraction. In: S. Muggleton, R. Otero and A. Tamaddoni-Nezhad (Eds.): Inductive Logic Programming, 16th International Conference on Inductive Logic Programming, ILP 2006, Santiago de Compostela, Spain, August 24-27, 2006. Series: Lecture Notes in Artificial Intelligence 4405 Springer 2007, 79-93.
M. Berardi, D. Malerba & M. Attimonelli (2006). Mining Information Extraction Models for HmtDB annotation. Proceedings of the International Workshop on Data Mining in Bioinformatics (DMB 2006), IEEE Computer Society, pp. 207-212.
M. Berardi, V. Giuliano, & D. Malerba (2006). Learning for Biomedical Information Extraction with ILP. Convegno italiano di Logica Computazionale (CILC 2006). Bari, Italy, June 26-27, 2006.
M. Berardi (2006). Towards Semantic Indexing of documents: a data mining perspective. Ph.D. Thesis, D. Malerba (supervisor), University of Bari, April 2006.